
By Karan Vohra
The stock market is a fascinating place that is balanced by the effects of countless intertwining agents. While to most of us it would seem chaotic and unstable, through varying methodologies, a few have discovered the underlying structure of it all. I’m eager to pursue the derivations of these methodologies and gain some experience in analysing complex systems. My goal is to create a trading algorithm that will outperform the market average by utilizing predictive models to determine future trends of non-linear economic systems in combination with deriving suitable strategies with respect to current system conditions, thus uncovering patterns of order in a widely entropic system.
Don Brittain pointed out some very interesting points regarding the correlation of the options and stock market. The general strategy he mentioned uses the options market as an initial vector for predicting the direction of the stock market. This strategy is something i’m interested in looking into and implementing as it can help me to create a better forecast. Typically options data is harder to come buy, however I believe the data will be invaluable as options trading is utilized more so by financial professionals.
I started by developing frameworks for data collection and organization. I’ve built various spiders that parse natural language data into an XML database. During this process, I discovered that while simple web scrapers can be utilized for parsing structured websites like Wikipedia or Wiktionary who “encourage” information collection, scraping dynamically driven websites like Bloomberg, which implements anti-bot protocols, requires a more “creative” approach. As such, I took interest in perspectivising the ethics of “mass” data collection which lead to an exploration of web exploitation and ethical reservation.
Currently I am focused on developing my NLP interface. When I first started researching the topic, I was immediately drawn to the ideas behind frame semantics. While something like sentiment analysis can provide some perspective on where certain financial events may lie on the spectrum of good and bad, frame semantics has the potential for a much deeper understanding. By drawing meaning from context, it creates connections within NL data that can define linguistic characteristics like ownership and characterization. Unfortunately I haven’t yet gotten the chance to implement this due to limited time and as such, I have decided to begin with sentiment analysis. My goal is to use sentiment analysis systems to determine relevance and general impact. I also plan on sourcing information for foreign market sectors for which I’ve been working on a multilingual lexical database.
The Age of PC
As devices enter the age of pc, they inherit the same traits were used to in our own computers. Within this growing culture, the locks on our door, the oven in our kitchen, and even the toilet in our bathrooms all currently, or eventually, will connect to the internet. For me personally, I’ve found most of these technologies gimmicky and unnecessary, however they continue to gain traction from the masses.
What does this mean?
Well, it’s common knowledge that our devices are becoming “smarter” and more versatile which in most cases is great for consumers! Unfortunately, this also means that all of these devices inherited the same security problems found in PC’s, for which there are many… Aside from hackers, virases, theft, ect…, privacy has become a major concern for many people and these devices only expose us further. Our data, the way we live our lives, has become an extremely valuable commodity within the big data sector, and despite the measures we take to mask ourselves, anonymity on the web no longer exists.
Mass Data Collection for Us Little Guys
Most big data companies are focused on collecting our personal data to bombard us with targeted ads as that’s where most of the money is. It is near impossible for a small business owner to gain access to this data without utilizing third party services like Amazon and Google, putting data pricing in the same boat as that of locksmithing. Frankly, I found myself annoyed that I would have to pay hundreds of dollars per month to gain access to a single data stream that tracked stock prices and needed to find a solution to this problem.
Complexity of Mass Data Collection Systems
The very first thing I learned when attempting to gain access to large quantities of data through various “info broker” domains is, they really don’t like it. Their ok with their users manually parsing their websites for information, however most domains have taken extreme measures to prevent bots scraping their websites, and for good reasons too. Bot systems themselves have been used maliciously for many reasons, and companies need to protect themselves from the stress a botnet can cause for their servers. Unfortunately, this means that low impact and well intentioned systems like mine have an increasingly difficult time accessing “free”online information.
Some current anti-bot practices:
-
AI Behavioral Tracking
-
Browser Profiling
-
Network Profiling
-
Cookie Tracking
-
User Profiling
-
Alternate/Fake Content
Ethics of Mass Data Collection Systems
There are only two options out there for accessing mass data:
-
Third Party Services (high cost, unverifiable trust/credibility)
-
DIY Systems (low cost, extremely difficult)
If you have the money, or need the supported infrastructure, third party services can be a great option for accessing data. Unfortunately for me, I don’t have hundreds of dollars to spend on data so DIY was the way to go.
I can’t talk in too much detail about my system as that is the culture of unethical programming, but check out this powerpoint that outlines the ethics of mass data collection:
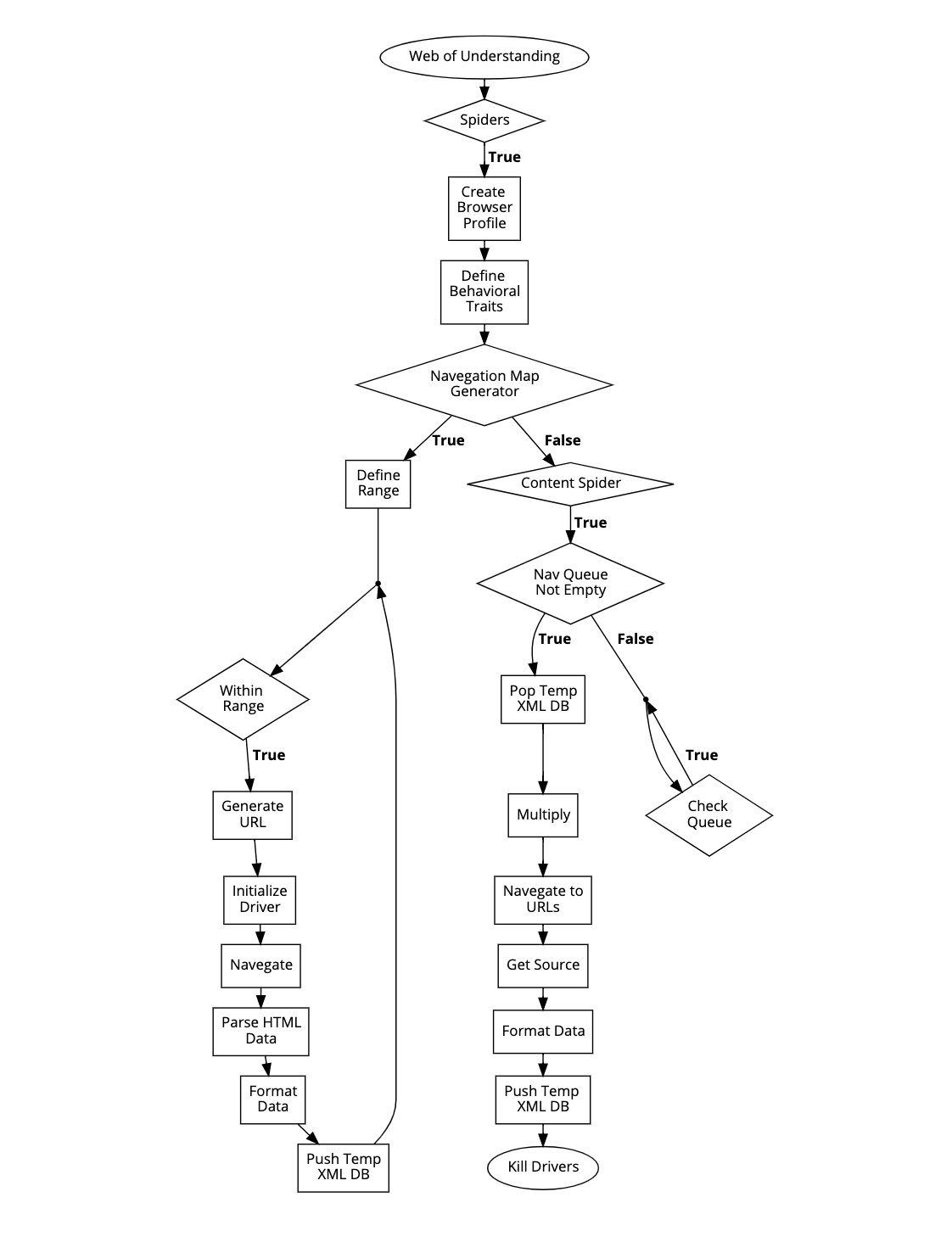
Spider Framework
– Navigation Mapping & Content Scraping