Max Fishman
This thesis paper addresses extensive research on how to augment the traditional data labeling workflow and annotation processing for machine learning and computer vision research, specifically for the development of new AI/ML tools for audio and visual artists.
This paper explores how image classification, a type of artificial intelligence where computers learn to identify objects in images, can be used in new and creative ways to market personal loans. We’ll discuss the challenges of collecting and labeling data for these artistic applications, and how open-source software and cloud computing can help us train powerful neural networks to understand and generate visuals specific to personal loan campaigns.
In order to train comprehensive AI models we need lots of accurately labeled data. This accurately labeled data is often hard to find or difficult to outsource. Art aims to provide artists and researchers with the tools they need to accurately and efficiently label vast amounts of data for machine learning and artificial intelligence computer tasks.
Features of Label.Art include:
Connect your labeling team with a custom or pre-trained ML Backend.
Visualize and compare predictions from different models and perform pre-labeling to speed up the labeling task.
Manage users to collaborate on your data labeling, machine learning, and data science projects.
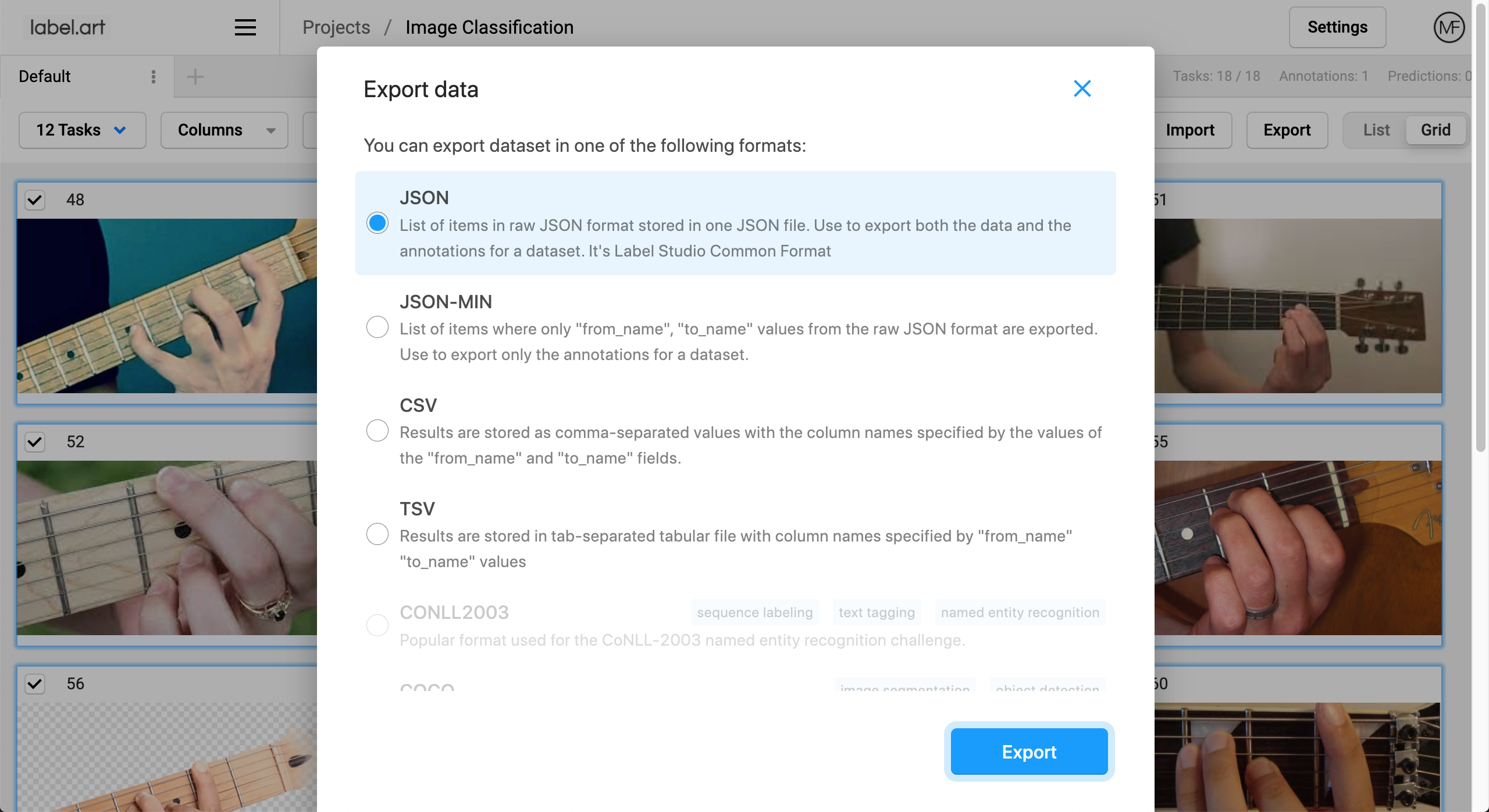
Cloud Storage: Amazon AWS S3, Google Cloud Storage, or JSON, CSV, TSV, RAR, and ZIP archives.
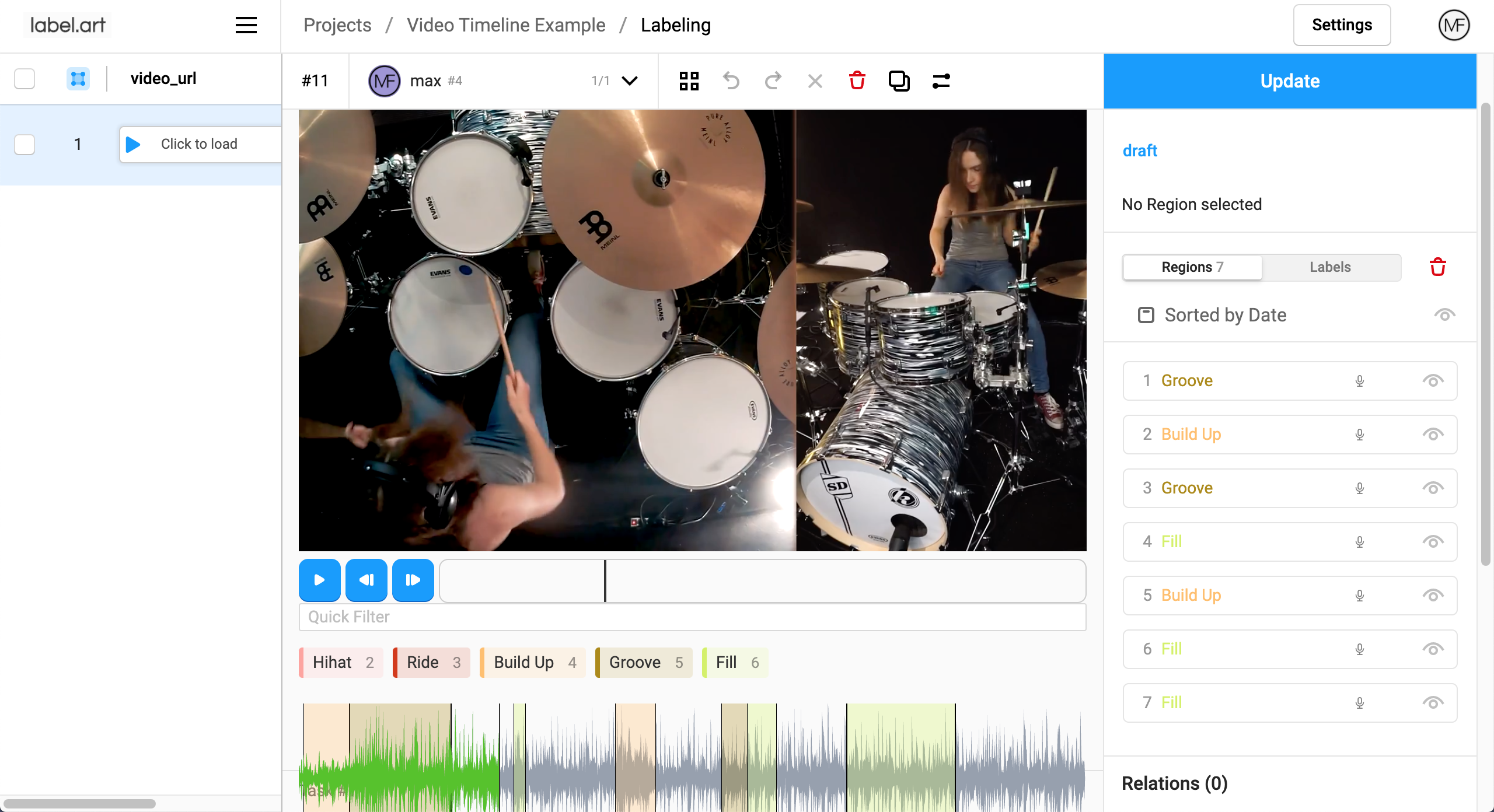
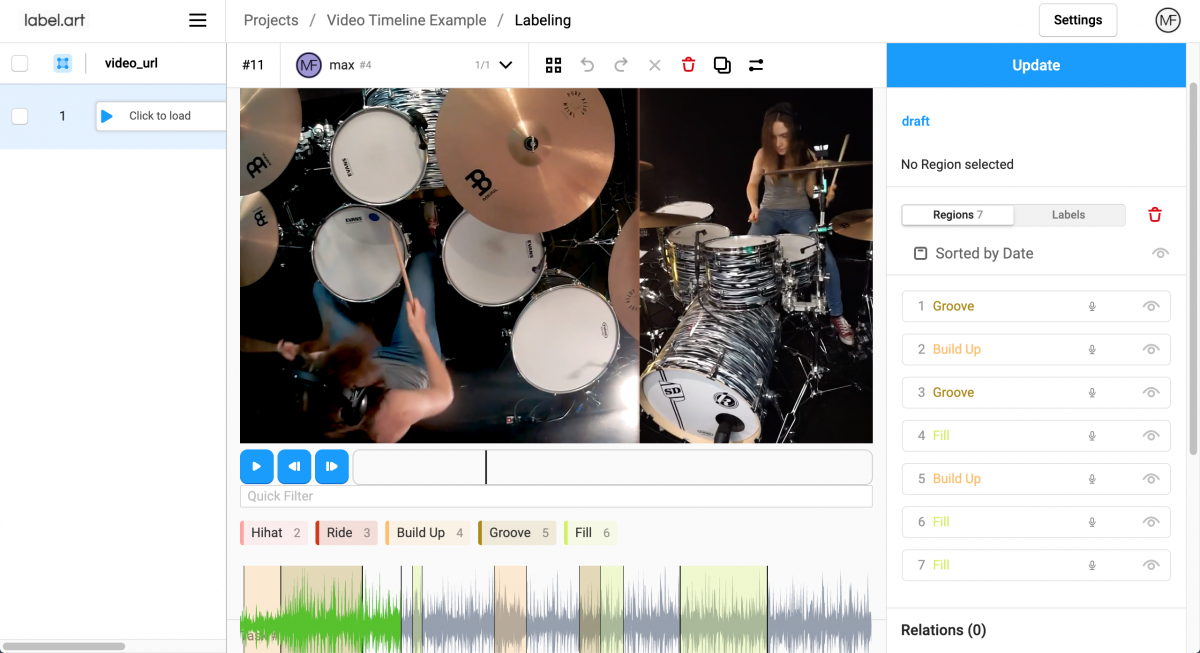
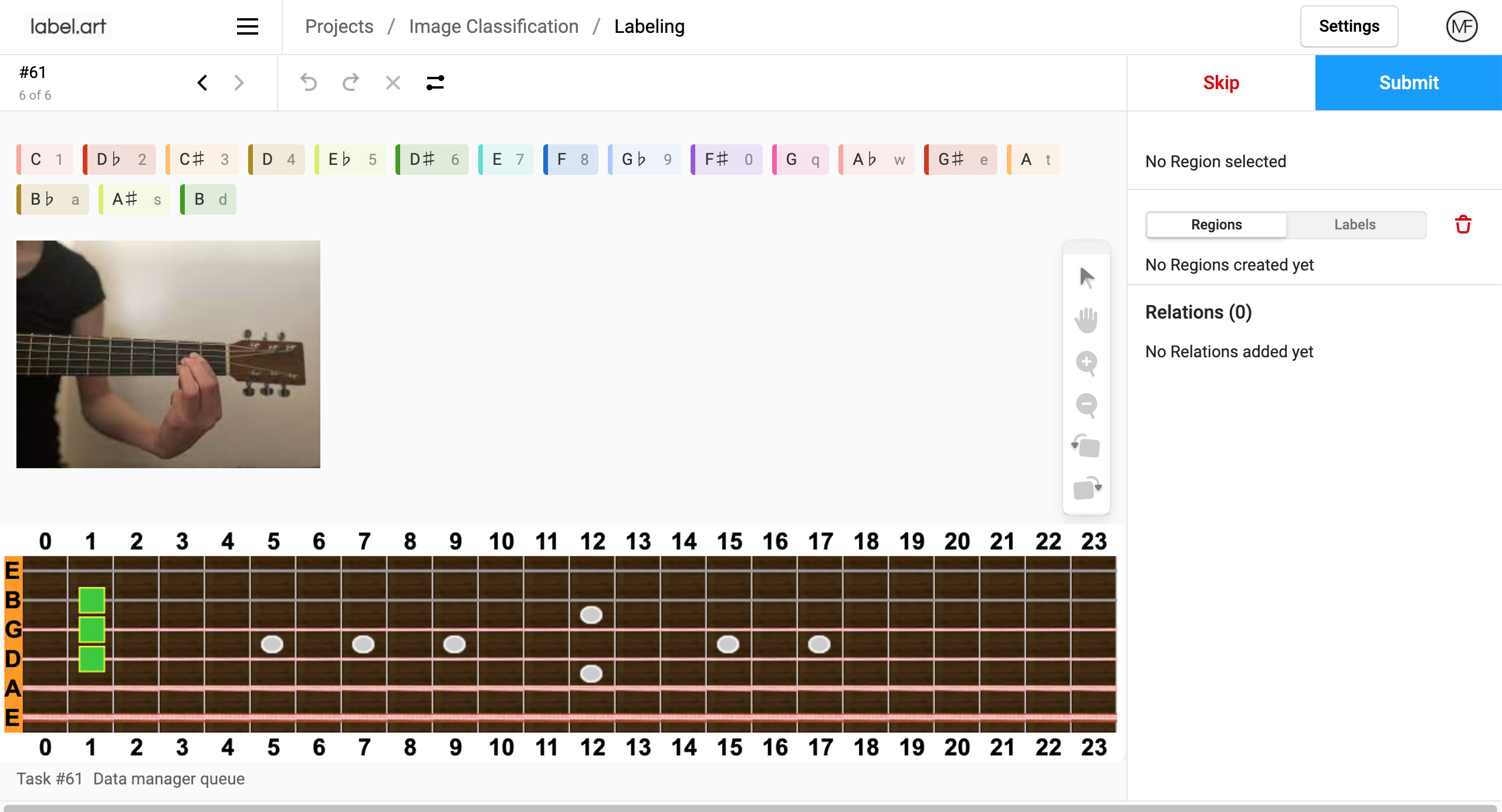
Custom Annotation Tools